Clustering Overview
Seq clustering increases query performance, reduces opportunities for data loss, and improves availability in the event of machine failures.
Clustering is not supported by all Seq subscription types. Please refer to the subscription tier details on datalust.co and contact us if you need help or further information.
Clustering Features
Seq clustering is designed for mission-critical servers with demanding availability, MTTR, and scale requirements.
High Availability (HA)
Clustering improves availability during planned maintenance, or unplanned hardware and software failures.
Seq clusters support zero-downtime upgrades. During planned software or hardware maintenance, shutting down a Seq node leaves the remaining nodes ready to receive ingested log data and serve queries with little-to-no perceptible availability gap.
In cases of unplanned downtime, including total and permanent loss of a Seq node, automatic fail-over will cause the cluster to self-heal in low tens of seconds. Built-in storage redundancy limits the potential for data loss in machine failure scenarios.
During outages and infrastructure issues, access to current log and trace data is crucial for fast recovery. Seq clusters recognize this and prioritize availability over durability, continuing to ingest logs and serve queries down to a single remaining Seq node. Clusters use integrated replication monitoring and proactive system alerts to limit unexpected data loss when replication is delayed.
Scale-Out
Scaling up, that is, running Seq on larger machines with more RAM, CPUs, and I/O throughput, is the easiest way to increase the capacity of a Seq instance. Practical considerations mean that larger instance sizes are not always desirable or readily available, and so scale-out provides an alternative method of adding compute resources to a Seq instance.
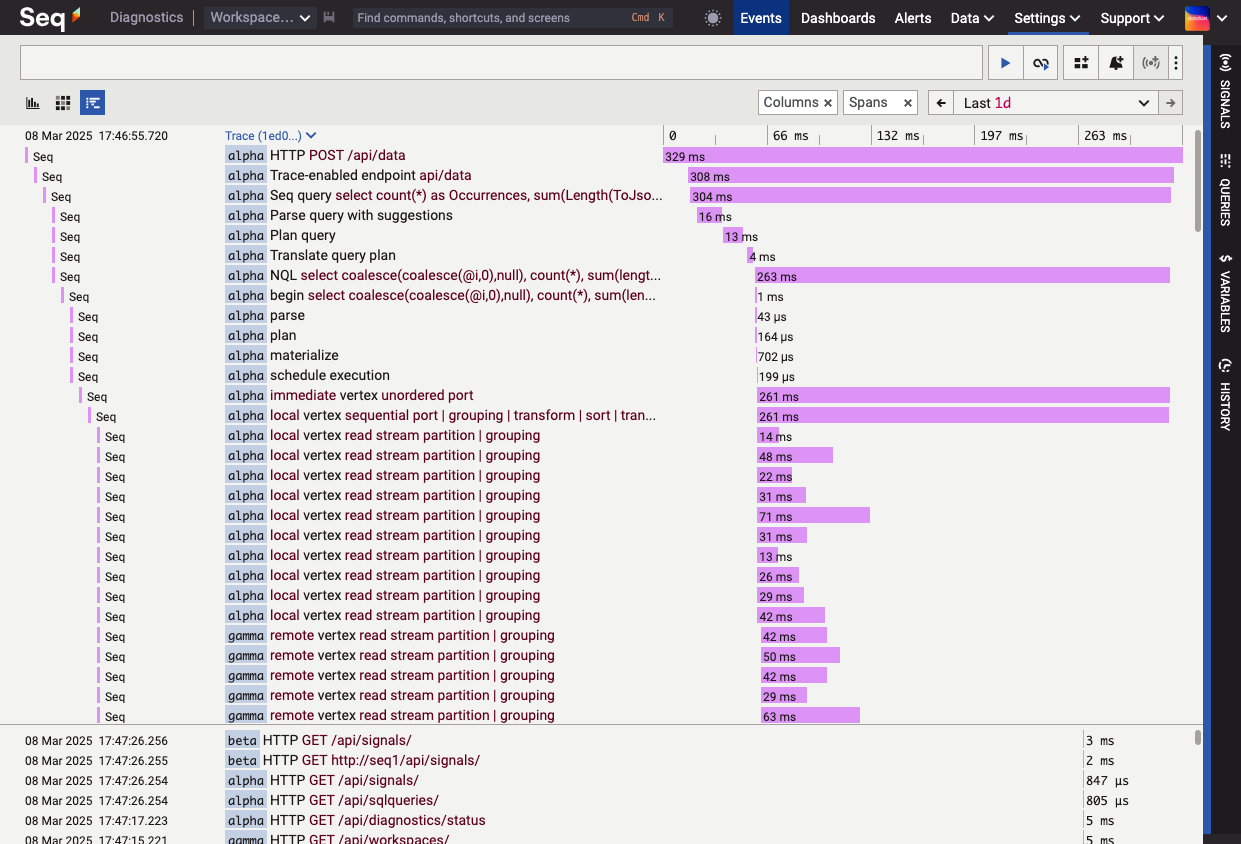
A cluster diagnostic instance, showing a trace of a Seq query executed on the cluster. The query has run vertexes on nodes alpha and gamma.
Internally, Seq represents queries as parallel dataflow graphs, with each "vertex" operating over a small partition of the underlying data store. When scaling out, vertexes are shared across the nodes participating in the cluster, allowing full utilization of the compute and I/O capabilities of each node.
Cluster Topology
A Seq cluster comprises:
- An HTTP load balancer,
- One or more Seq nodes, each with local persistent storage, and
- A shared Microsoft SQL Server or PostgreSQL database.
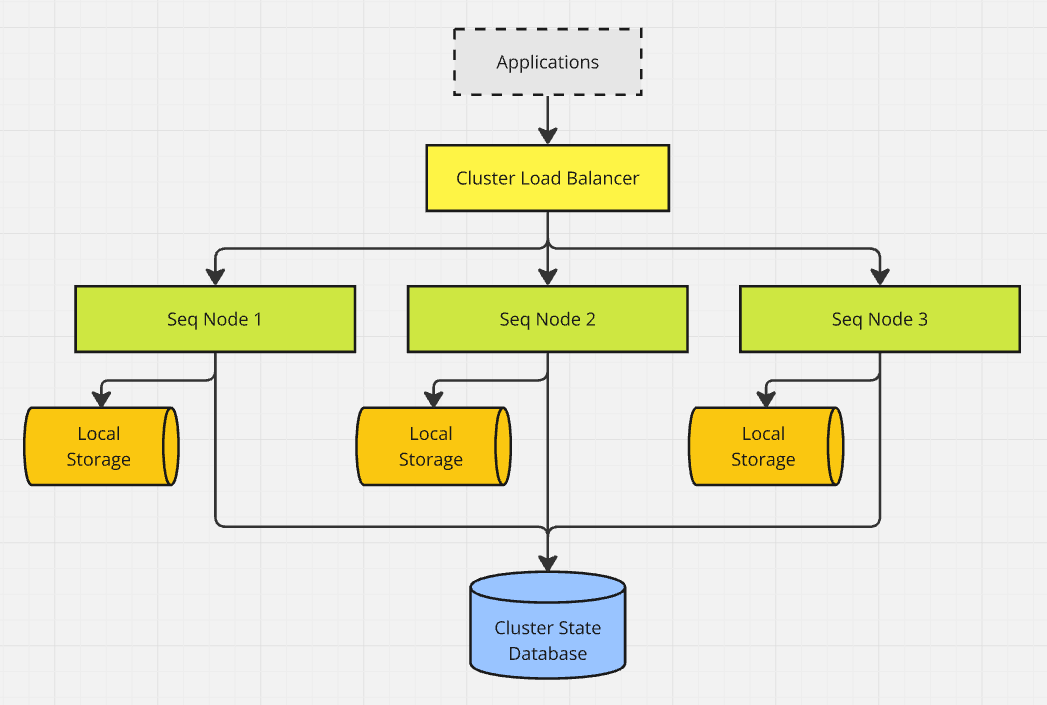
Ingestion traffic and API requests from the outside world reach the load balancer. The load balancer spreads traffic over the in-service Seq nodes, and these coordinate internally via cluster networking to serve requests. The backing database is used for shared metadata storage (users, signals, dashboards, etc.), and as a consensus broker for cluster state changes.
See Setting up a Seq HA Cluster for detailed information on the requirements for each component.
Clustering vs Legacy Disaster Recovery (DR)
Seq versions up to and including 2024.3 support a limited two-node clustering capability that provides storage redundancy and manual fail-over for disaster recovery purposes. Legacy DR clusters do not support scale-out: all work runs on the leader node.
Seq DR clusters can be upgraded to HA clusters in-place. But, because the earlier DR implementation is unable to support the coordination features required for HA clustering, manual intervention is required in order to upgrade these clusters. See Migrating Legacy DR Clusters to HA for instructions.
Updated about 1 month ago