Indexing
Indexes potentially make queries faster by reducing the volume of data from disk that queries must search. Each index adds a small amount of overhead to the server.
Seq provides two different types of indexes. Signal Indexes are created automatically with Signals. They help Seq to find events that match the signal. Expression indexes are created by indexing a property of an event. They help Seq to find events by searching for a value of the indexed property.
Maintaining indexes consumes IO bandwidth and CPU time that would otherwise be available for queries. It also consumes a small amount of disk space to store the index.
Signal Indexes
Signal indexes precompute the location of events matching their signal.
When a search is initiated with an active signal Seq is able to use the index to only search the parts of the log that are known to have hits. When multiple signals are active Seq can intersect them to further the reduce the search area. The more signal indexes that are active to narrow down a search, the less data Seq needs to search.
To take advantage of indexing, one or more signals should be selected before issuing a search or query, and should be used to select source data when creating dashboards or alerts.
Signals are most effective when they select a small proportion of the log. The benefit provided by an index will also be influenced by the size of the events being searched, and the overlap between signals.
Creating a Signal Index
Signal indexes are created automatically when a signal is created.
Removing a Signal Index
Signal indexes are removed when the associated signal is deleted.
It is also possible to delete the signal index, but keep the associated signal. To do this, edit the signal, toggle the INDEXING option to Off, and save the signal.
Expression Indexes
Expression indexes improve the performance of equality searches by the indexed property. For example, if there exists an Expression Index on the ServerName property then a search such as ServerName = 'us-east-1-df68'will automatically use the index. With the index, Seq is able to restrict the search to the parts of the log that contain events having a ServerName property with the value us-east-1-df68.
The efficiency of an expression index is determined by the frequency with which the value being searched for appears in the log. If every event has a ServerName property with the value us-east-1-df68 then the index will not be used, and should be removed. If one in every thousand events has a ServerName property with the value us-east-1-df68 then searches using the index will be approximately 1000x faster.
Expression indexes are not used by the other comparison operators,
<,>,<=,>=and<>.
Creating an Expression Index
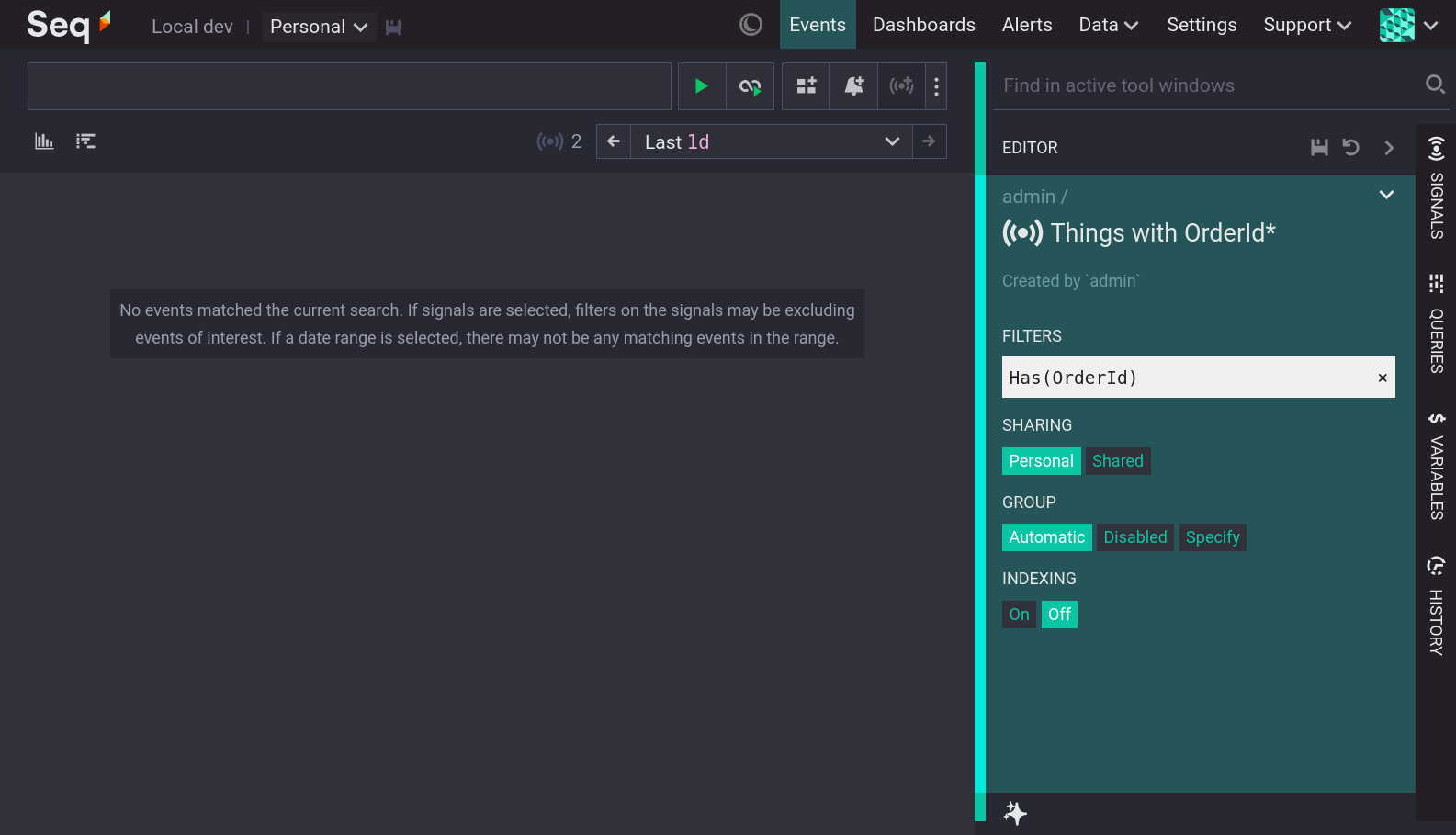
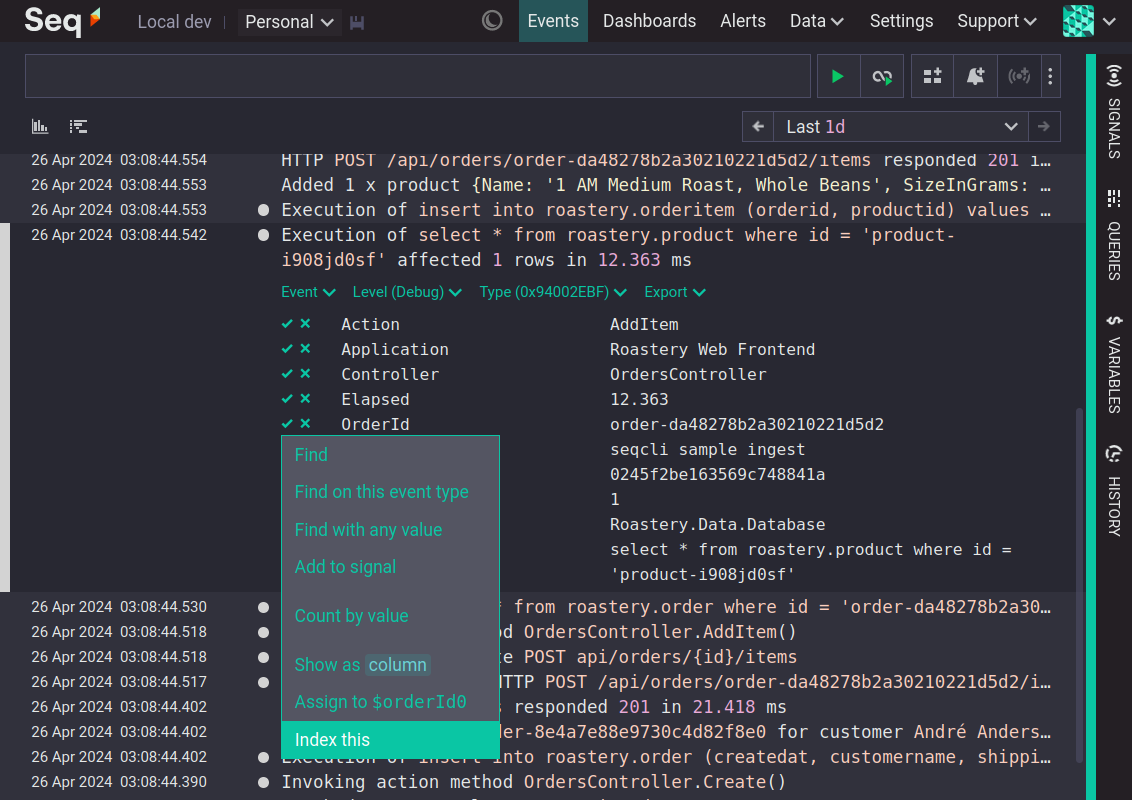
From Events, expand an event and open the ✔menu for the property to index. If the property does not already have an index then the 'Index this' action will be available. Choosing 'Index this', and accepting the subsequent dialog, will queue a job to create an index for that property. For servers with a lot of data it may take several hours to complete the index.
Users with sufficient permission can inspect a list of all indexes at Data > Indexing.
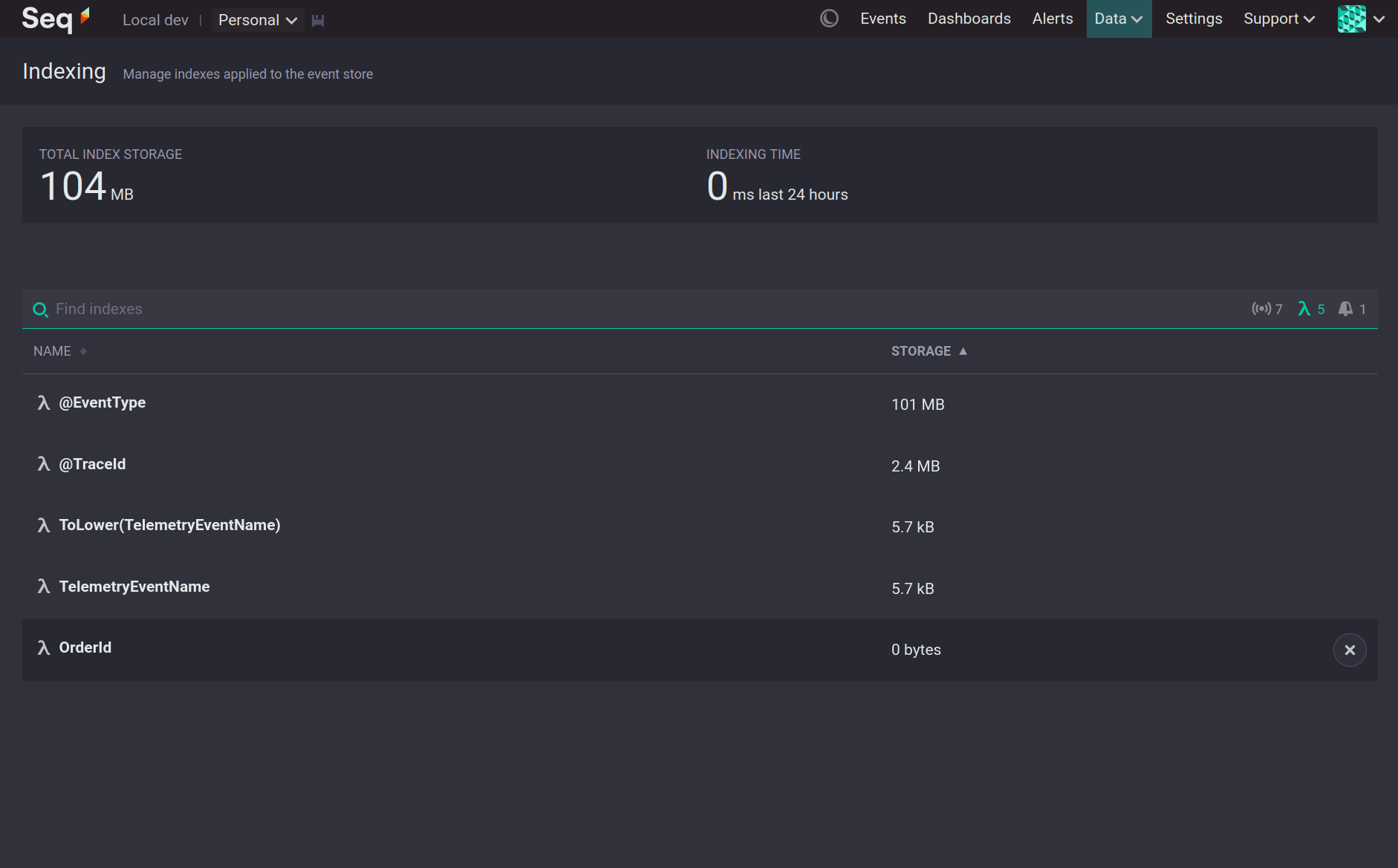
For each index the list includes the amount of storage space currently used.
The progress of indexing can be viewed at Data > Storage.
Removing an Expression Index
Removing an expression index queues a job to delete that expression index. To delete an expression index, navigate to Events, expand an event and open the ✔menu for the indexed property. Choose Delete index and confirm the dialog box. Alternatively, expression indexes can be deleted from Data > Indexing.
Alert Indexes
Alert indexes use the same underlying functionality as signal indexes, except that they are created automatically with new alerts, matching the alert's where clause. For example if an alert is created with the where clause RequestId = '6649099ee89d392c33e668' and @Level = 'Warning' then Seq will create an alert index for the predicate RequestId = '6649099ee89d392c33e668' and @Level = 'Warning'and use it when checking the alert.
Removing an Alert Index
There is no capability to remove an alert index, however, they are removed when their alert is deleted.
Indexing considerations
- Indexing won't be applied to any data written in the last hour: this prevents churn caused by events arriving slightly late, or when the originating application is on a machine with clock drift.
- Indexing also doesn't trigger until at least 160 MB of contiguous data are available to be indexed.
- When signals change, recent data is reindexed first: this means that if, say, an automated process (or users) modify signals constantly, then some of the old data may be left with stale indexes (this won't impact correctness, only performance).
- Indexing competes with retention policy processing time; so, if retention policies are running efficiently, the time remaining will be used for indexing; if retention policies are running at capacity (this would be indicated by single-digit "headway" numbers in the logs) then indexing won't run.
- Historical writes, for example importing a day's worth of logs with timestamps one week ago, won't be indexed unless retention processing compacts them into the indexed log stream (they will be searchable, but indexes will not boost performance over the imported range).
Updated 5 months ago