Search and Analyze Logs and Traces
A primer on the Seq Query Language
This page covers everything you need to know in order to understand your systems, find bugs, and spot trends using telemetry data in Seq!
The Seq query language serves two closely related, yet distinct, purposes. First, it's the foundation of quick and easy event searching: finding structured events that match some criteria. Second, it's a language for log analysis: computing statistics and revealing patterns in aggregated log data.
As a language for log search, the Seq Query Language needs to be ergonomic, forgiving, and terse. Log search is usually ad-hoc and exploratory - and often done in a hurry!
As a language for log analysis, the language must be clear and precise. Especially when results are numeric or aggregated from many records, the underlying computation needs to behave exactly as the user expects. Log analysis is much more like programming in this regard.
Seq's query language meets both these goals through two modes, based around a common, core syntax. As searching for events is the first thing most developers do with Seq, it's conventional to introduce the simpler search expressions first, before examining queries for log analysis.
Search expressions
Many diagnostic sessions start with an error. Something's gone wrong, an error message or error id has been reported, and application logs are often where we turn to track down the root cause.
If you type an error message directly into Seq's search box, you'll very probably find it:
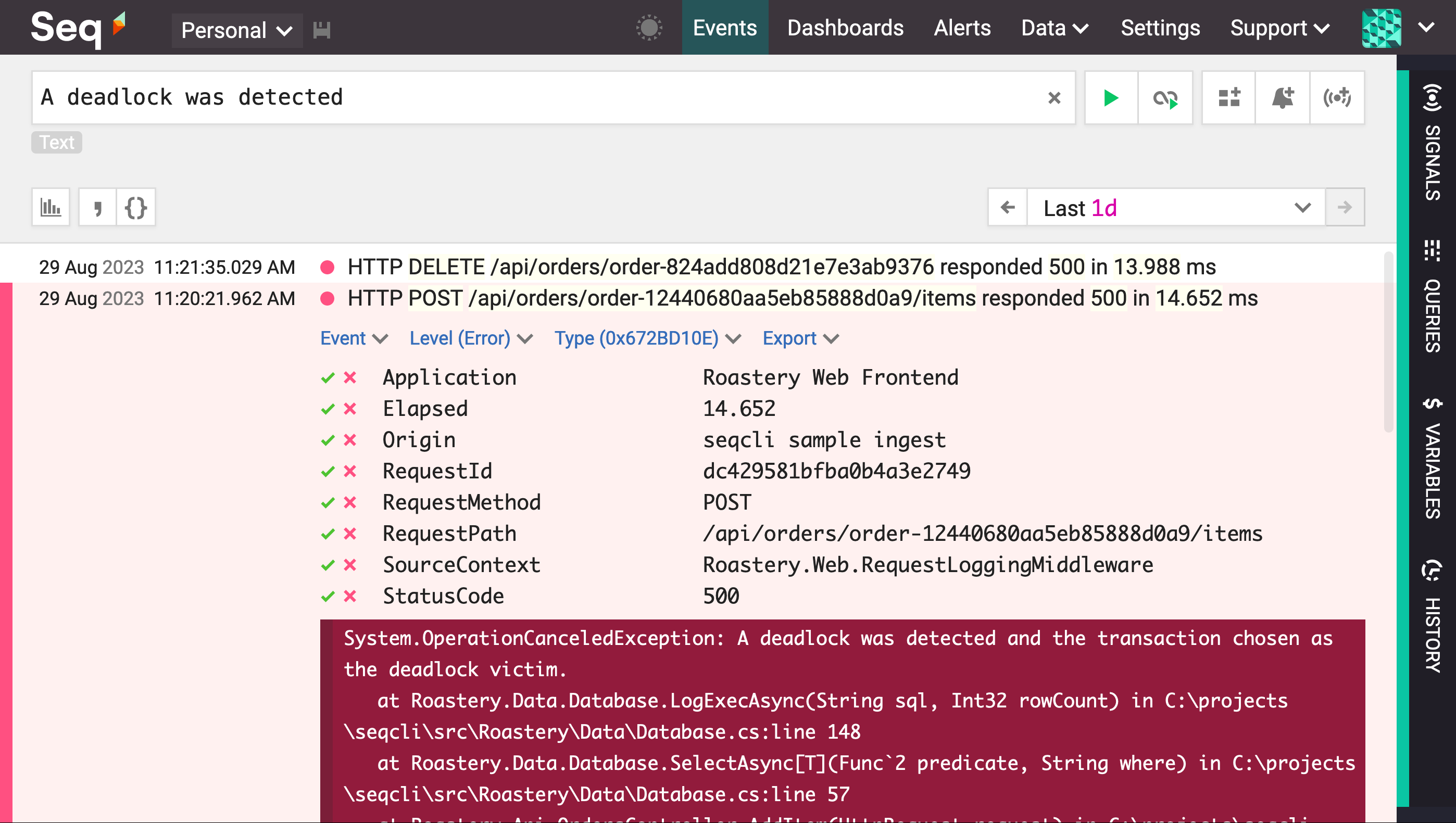
A text search, showing some errors
The expanded event shows a matching exception/error trace, in the darker red box.
Search results in Seq are always in time-descending order: the events at the top are the newest, getting older as we read down the page.
Application logs can be a very big haystack indeed. To pick out the needles, simple text search isn't always enough. If we want to filter out the warnings and see only events that resulted in an error, we can write a search expression ourselves that excludes them:
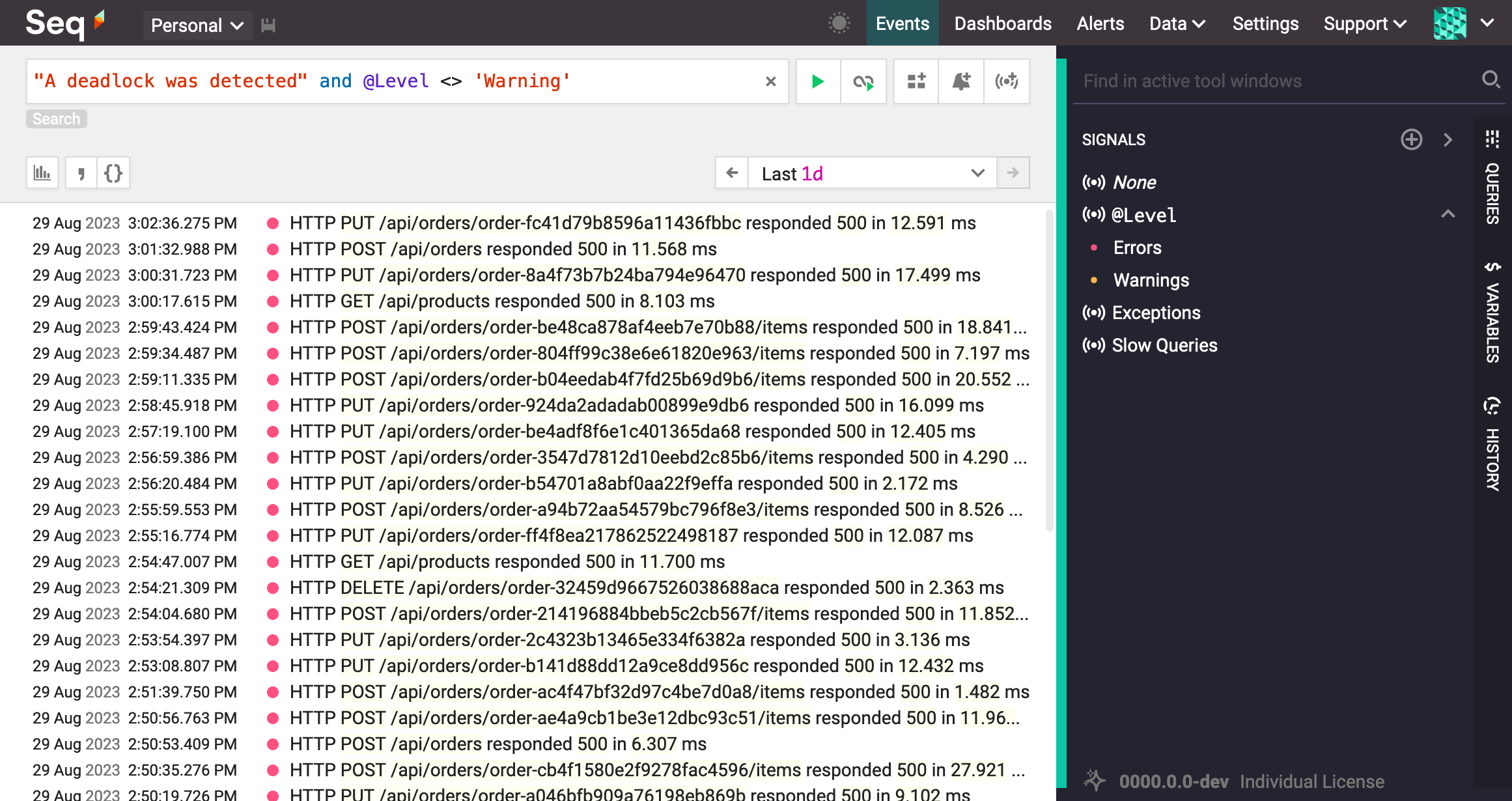
A search expression, "A deadlock was detected" and @Level <> 'Warning'
Let's break down this expression and look at each part. Along the way we can introduce a number of core features of the Seq query language.
Logical and comparison operators
If you've worked with SQL you'll immediately notice the familiar operators and and <>. Seq uses SQL-style operators in expressions.
The comparisons are = (equality), <> (inequality, "not equal to"), <, <=, >, and >= in their usual roles. In search mode, Seq will also accept C-style == and !=, but these are convenience aliases and are not supported in query mode, so you should prefer the SQL-style versions.
Comparisons with properties are always false if the event does not have that property. E.g. Name <> 'Peter' is false if the event does not have a Name property.
The logical operators are and, or, and prefix not. Just as with the logical operators, C-style &&, || and prefix ! are accepted for convenience.
Search expressions can use variables for convenience.
Built-in Properties
@Level is a built-in property. This means it isn't part of the log event's "payload" but a special, well-known piece of data that is tracked separately for every event.
If we had written Level <> 'Warning' instead, Level would refer to a regular property of the event (which doesn't exist, in this case).
There are several built-in properties like @Level. The most important are:
@Timestamp— the time an event occurred, stored as an opaque numeric value; every event in Seq must be timestamped@Message— a message associated with the event; event's don't have to have human-readable messages associated with them, but it's much friendlier to read logs with meaningful messages, so Seq encourages it by making@Messagefirst-class@MessageTemplate— structured log sources that support message templates can send the template that produced a log event and Seq will make it available in this built-in property; the message template is like a "type" for a structured event, and Seq computes a numeric@EventTypeproperty based on it to simplify querying events by type@Exception— just like messages, log events don't necessarily all have associated exception information or stack traces, but these details are important enough to get their own field, and@Properties— the generic structured data associated with the event, in a key-value map.
Strings and text fragments
Remaining in our example expression are two bits of text, the original error message we were searching for, and 'Warning':
"A deadlock was detected" and @Level <> 'Warning'Despite their similarities, these are different constructs in Seq's query language.
"operation timed out", double-quoted, is a text fragment. It's not compared with anything: it represents some fragment of text that might appear in the event's message (or exception/stack trace). Text fragments are handy for quick searches that need a little more detail: "deadlock" and not "detected", for example. Text fragments are always matched in a case-insensitive manner.
'Warning', with single quotes, is a string. It acts and is used just like any normal programming language string.
String operations and the ci modifier
ci modifierWe've already seen equality and inequality, both of which can be applied to strings. Seq supports more sophisticated comparisons using like and not like:
@Level not like 'Warn%'The like operator, borrowed also from SQL, supports % (zero-or-more characters) and _ (one character) wildcards, enabling prefix, suffix, substring, and more complex comparisons.
The universal case-insensitivity modifier ci turns whatever operation it is applied to into a case-insensitive one. The ci modifier is a postfix operator that works with any string comparison, =, <>, like, in, and more:
Subsystem = 'smtp' ciApplied to an equality operation like this we'll match values of the Subsystem property in any character case: smtp, SMTP, Smtp, etc.
If we go back to our original example, "A deadlock was detected", we can express this using string comparisons as:
@Message like '%A deadlock was detected%' ci or
@Exception like '%A deadlock was detected%' ciRegular expressions
To round out our discussion of strings and text, regular expression literals are worth a quick mention. These use /-delimited syntax, familiar from JavaScript:
/o.*n/The example above matches events that contain any text delimited in by the characters o and n: 'only', 'operation', and so-on.
Regular expressions can be used just like text fragments, as above, and they're also supported by overloads of = (full string match), <> (not a full string match), plus some of the built-in functions we'll look at later:
Source = /(Microsoft|System).*Internal/Data types
The core data types in the Seq query language include:
'single quoted'- strings (which we've already seen); the quote character'can be escaped by doubling:'Can''t'123,0.45,0xc0ffee- numbers, internally represented as 128-bit decimal values30d,100ms- durations, specified as whole numbers ofdays,hours,minutes,seconds, ormsmillisecondstrueandfalse- Booleans[1, 'test', true]- arrays with[0]zero-based numeric indexing{ace: 1, 'beta gamma': 23}- object literals with string or identifier keysnull
The last one, null, is a value in the Seq query language: Result = null will return true if the result property exists and has the value null. If we want to test for existence of a property, we can use the built-in Has function: Has(Result).
It's worth mentioning that behind the scenes, durations are just numbers. Durations are handy, though, because they're on the right scale to use in comparisons with @Timestamp and now(): for example @Timestamp > now() - 30d. See Working with Dates and Times for more detail.
The properties of an object can be accessed using .MemberAccess or ['indexer'] syntax.
Functions
Functions fill their normal role and use Name(Arg0, Arg1, ...) call syntax. There are many built-in functions, that work on individual values; some of the more frequently-used are:
coalesce(a0, a1, ...)- return the first non-null argumentDateTime(s),TimeSpan(s)- parse date and time strings into their internal numeric representationsKeys(o),Values(o)- return an array of all keys or values in an objectLength(o)- the length of a string or arraynow()- the current time, as an internal numeric timestampSubstring(s, start, count),StartsWith(s, substring),EndsWith(s, substring),IndexOf(s, substring),LastIndexOf(s, substring)- extract and look for substrings within stringsToJson(o),FromJson(s)- convert to and from literal JSONToIsoString(t)- convert an internal numeric timestamp into an ISO 8601 stringToUpper(s),ToLower(s)- change the case of a string
Null
To find events that have a TaxAmount property:
Has(TaxAmount)
// or
TaxAmount is not nullTo find events that do not have a TaxAmount
not Has(TaxAmount)
// or
TaxAmount is nullTo find events that have a TaxAmount property that has the value null:
TaxAmount = nullCollection operations
Structured log data often includes array- or object-like values that are interesting for search and analysis.
Seq has a few convenient shortcuts that make it pleasant to deal with these. First up, a SQL-style in operator makes it easy to match values in a literal array:
@Level in ['Warning', 'Error']Or in an array attached to a log event:
'seq' in Post.TagsThe in operator supports the ci modifier, but is otherwise limited in the kinds of comparisons that can be performed. To check whether any tag in Post.Tags starts with the literal 'seq', the query language implements wildcards in [] indexer operations on arrays and objects:
Post.Tags[?] like 'seq%'The ? wildcard is read as "any", while * is "all". Wildcards come into their own when working with nested data.
Order.Shipments[*].Items[*].TaxAmount > 0The expression above finds events with an Order property where all items in all shipments were taxable.
Lambda
The two wildcard searches above can be expanded into lambda syntax using Some() and Every():
-- Post.Tags[?] like 'seq%'
Some(Post.Tags, |tag| tag like 'seq%')
-- Order.Shipments[*].Items[*].TaxAmount > 0
Every(Order.Shipments, |shipment| Every(shipment.Items, |item| item.TaxAmount > 0))Lambda syntax is more flexible than what can be achieved using wildcards. The comparative verbosity shows why wildcards are great for quick searches during diagnostic sessions, however.
Conditionals
Seq supports conditional expressions using if/then/else syntax:
if Quantity = 0 then 'None' else 'Plenty'Conditionals can be chained:
if Quantity = 0 then 'None' else if Quantity < 20 'Some' else 'Plenty'Conditionals more commonly appear in queries than in search expressions.
let bindings
let bindingsSeq uses let bindings to give names to values in expressions:
let |hour: datepart(@Timestamp, 'hour', 10h)| hour < 8 or hour >= 17Multiple names can be introduced in a single let expression, separated by commas:
-- Evaluates to 3
let |a: 1, b: 2| a + bQueries
We've seen how search expressions can be used to match events. The more sophisticated mode of interaction with Seq is by using queries to analyze structured logs.
All queries in Seq begin with the keyword select, and all of them produce a result with rows and columns.
Projections
The simplest useful queries project a list of columns out from event properties. Let's look the the fifty slowest API responses from a web app:
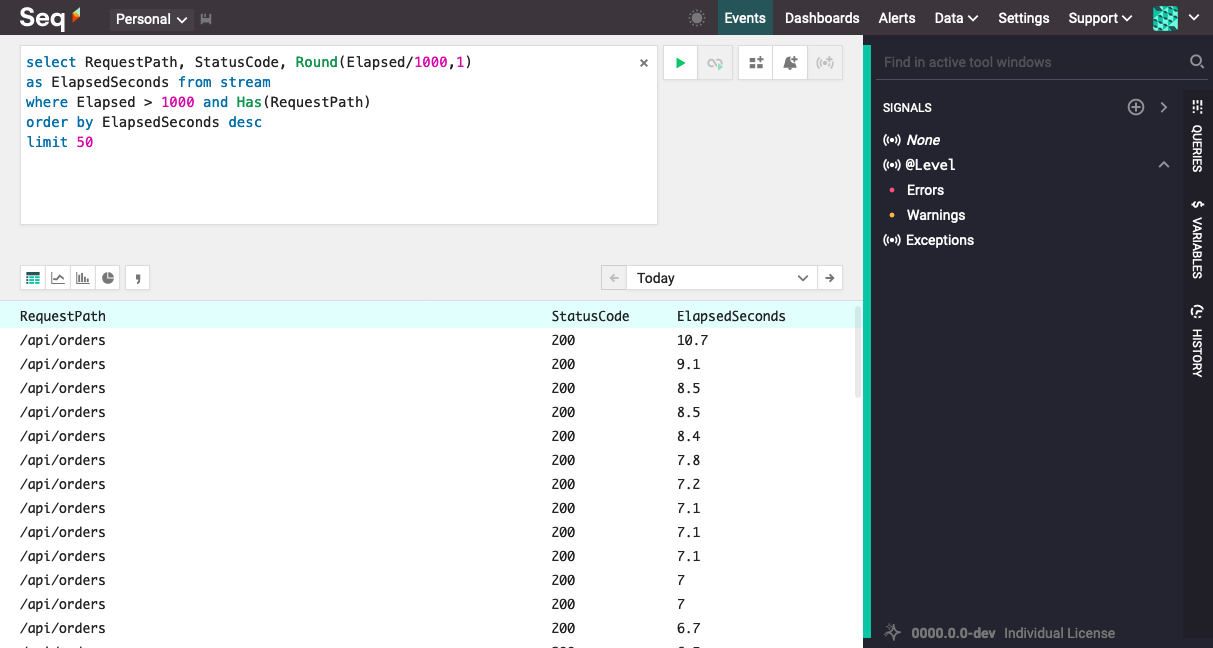
Query projection
If you're following along and typing this into the Seq query editor,
Ctrl + Enterwill insert newlines.Queries can include comments, which start with
--and continue to the end of the line.
The column list following select supports aliases, for example RequestPath as endpoint, and complex expressions, for example Substring(RequestPath, 0, IndexOf(RequestPath, '/')) as area.
The from stream clause specifies that the query reads from the stream of log events in the Seq event store.
The optional where clause predicate supports complex expressions - everything we saw in the search expressions section above - with the exception that only SQL-style operators are allowed (and vs. &&), and text fragments are not allowed (so "operation timed out" needs to be written as @Message like '%operation timed out%' ci).
To improve the performance of a query take advantage of Indexing by creating a signal for the filter expression Elapsed > 1000 and Has(RequestPath), select the signal, then run the query.
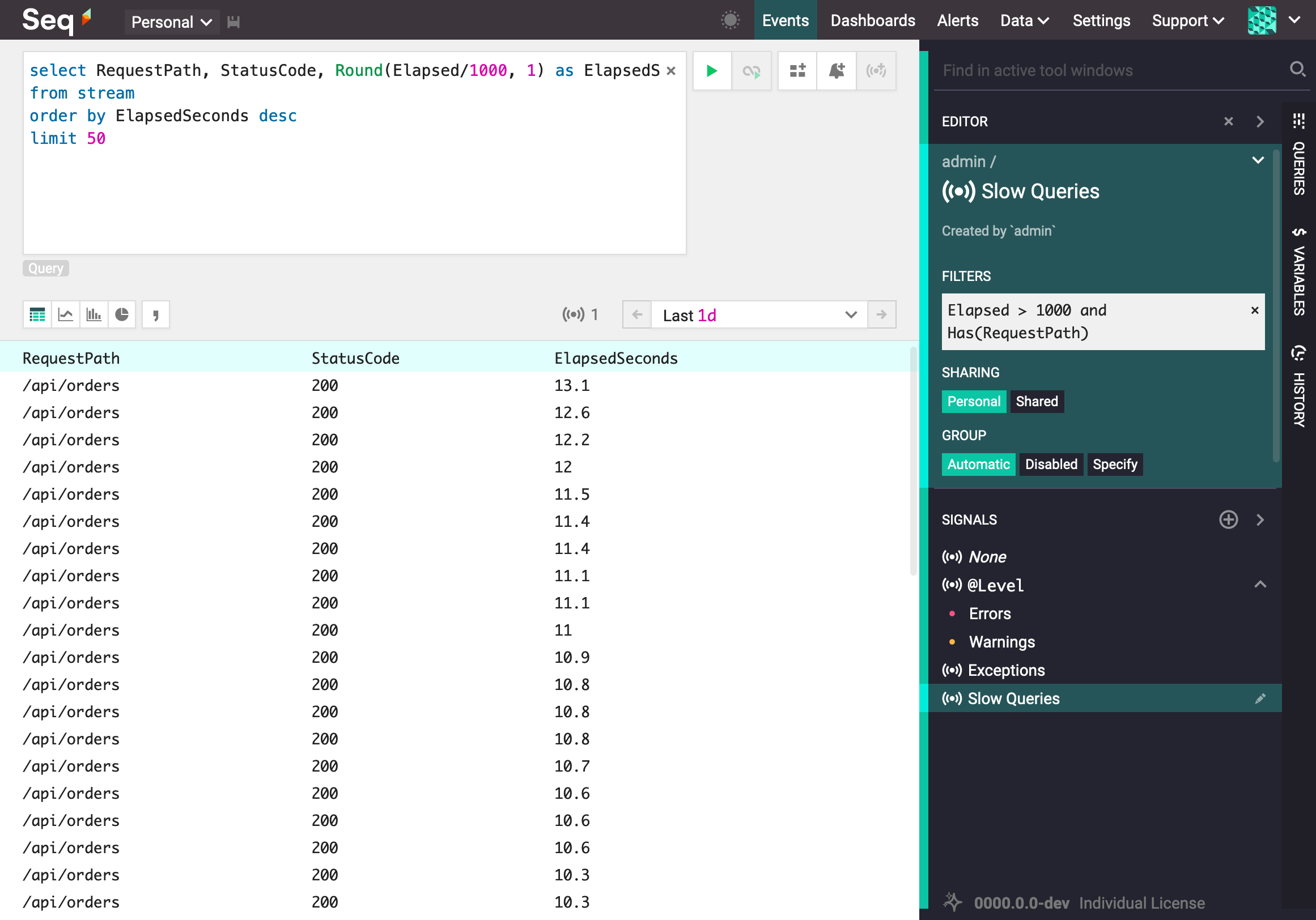
Applying a Signal Index
The order by clause is optional, and supports both ascending and descending orderings over the columns in the column list. Orderings can include expressions - coalesce(StatusCode, 500) — but columns that are themselves complex expressions need to be aliased in order to refer to them in orderings.
The final clause, limit, is also optional - but Seq will reject the query if its internal default row limit is hit, so it's necessary when queries produce large result sets, and to conserve server resources and network bandwidth. The limit clause works just like top, if you're familiar with the Microsoft SQL Server way of doing things.
We're running this example over the "Slow Queries" signal so the result set is limited to consider only events that are matched by the signal.
Aggregations and grouping
Digging deeper into web application response times, our "top fifty" list is useful for finding outliers, but it's hard to tell whether the slow responses we're looking at are representative of real user experience on our site, or just freak occurrences caused by transient issues.
Finding trends in large numbers of events is a task for aggregate functions like count(), min(), max(), mean() and percentile(). You can compute aggregates over the whole stream of events being examined, for example:
select count(*)
from stream
where Elapsed > 1000In this case, it's more useful to see results grouped by the API endpoint that's being hit, so we'll look at 99th percentile response times and use group by to slice the event stream up:
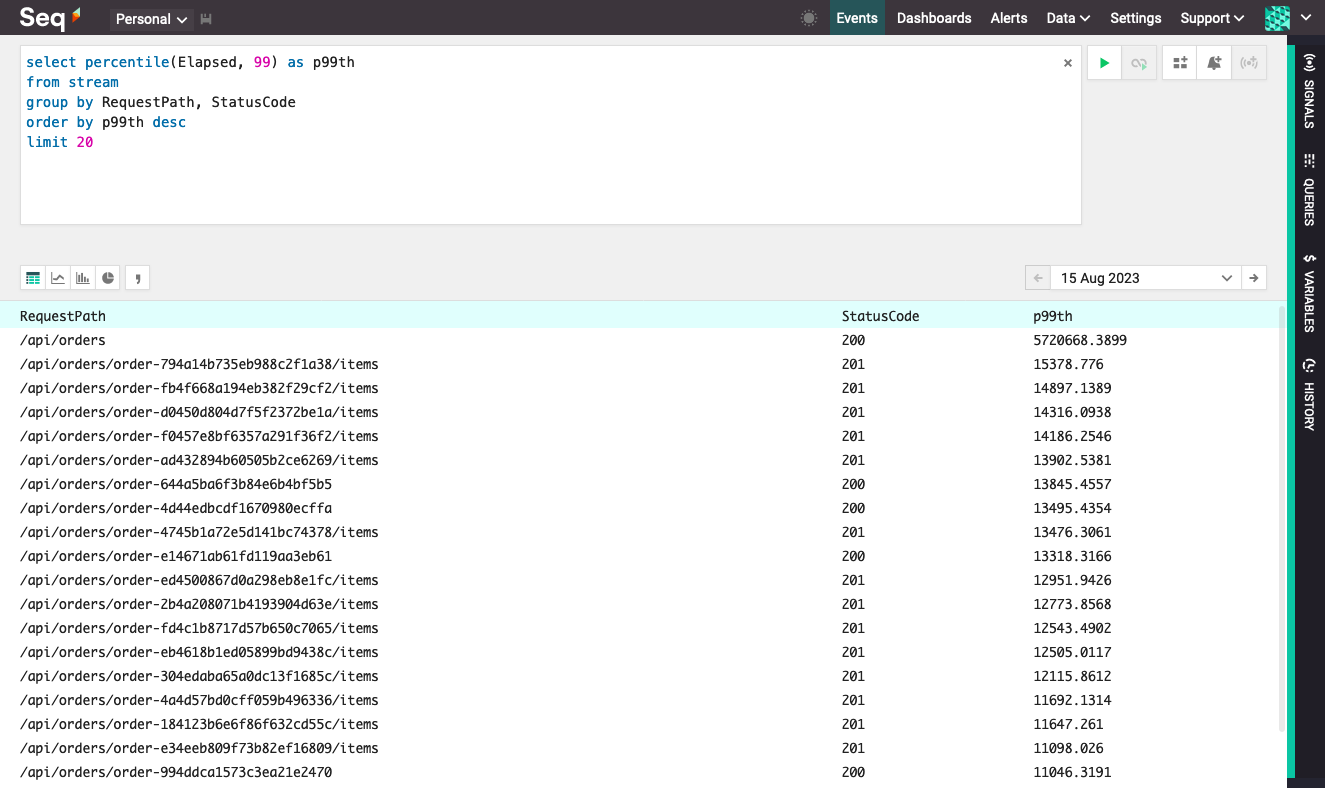
The query select percentile(Elapsed, 99) as p99th from stream group by RequestPath, StatusCode order by p99th desc
The result set has three columns, despite there being only one in the select column list: groupings are also columns in the Seq query language.
If the result set is large, a limit or having clause — for example having p99th > 1000 — can trim it down and save some bandwidth.
Aggregate functions
The built-in functions we saw earlier operate on single values. Aggregate functions operate on sets of values; Seq provides:
any(p)andall(p)- evaluate totrueif the argument predicate evaluates totruefor any/all events in the setcount(p)andcount(*)- thecountaggregation can be used to count all events (*), or just those for which the argument predicate evaluates totrue, for example `count(@Level = 'Error')distinct(e)- collect unique values of the expressione; a special formcount(distinct(e))returns the count of distinct values rather than the values themselvesmean(e)- the arithmetic mean,sum(e) / count(*); in aggregations likemean()that operate on numbers, only numeric values forecontribute to the result (ife, for example, evaluates to a string, then it contributes neither to the sum nor the count of values)min(e),max(e)- minimum and maximum values of an expressionpercentile(e, p)- a nearest-rank percentile, which computes the value of expressioneunder whichppercent of value fallsum(e)- the sum of values ofefirst(e),last(e)- the first and last values ofewithin the set
Timeseries
Our query above shows the slowest responses over a time range. If we want to see how responses evolve over time, we can generate a timeseries by further grouping over time intervals with a time() grouping. The time() grouping accepts a duration and groups events into to buckets of that size:
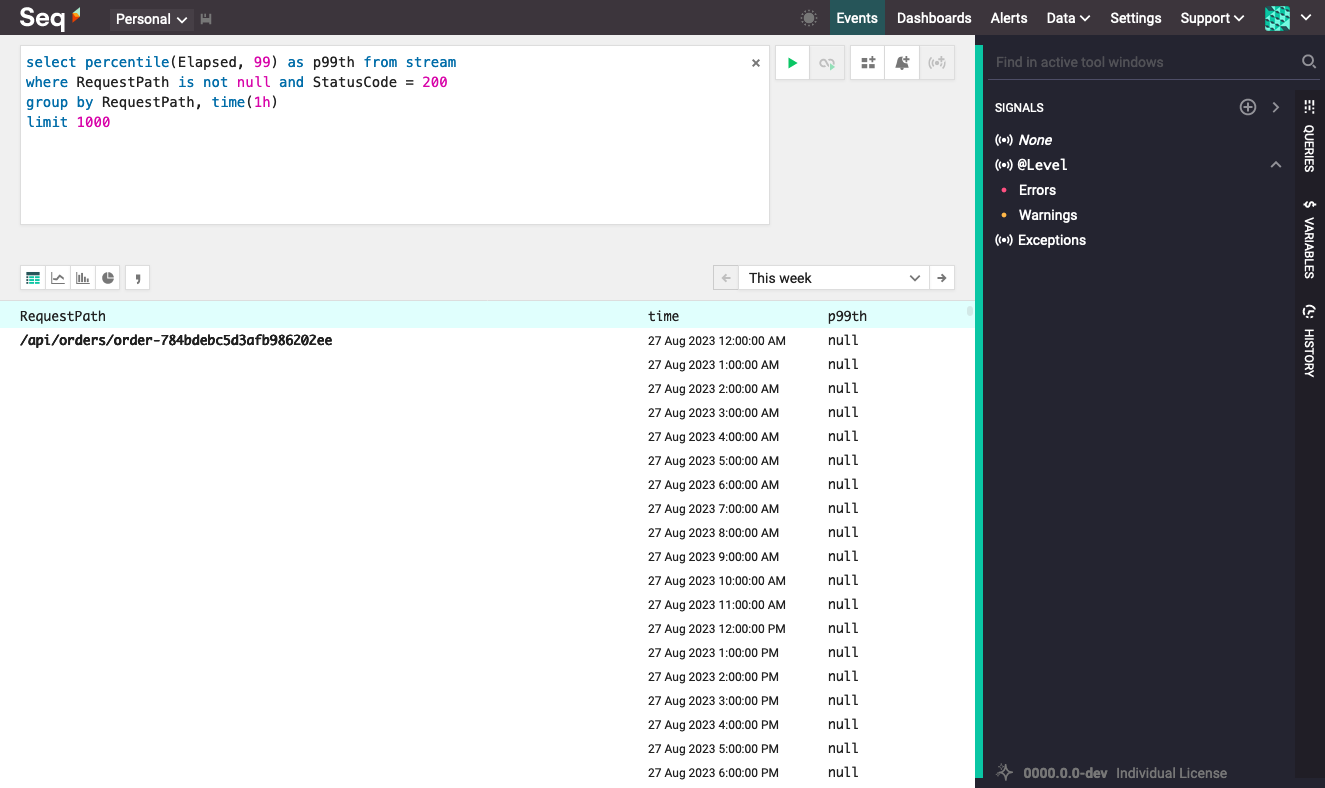
Grouping by time
You can chart timeseries results in the Seq user interface by pressing the tiny chart button above the result set. If you group by more than one dimension, just remember to make the time() grouping last:
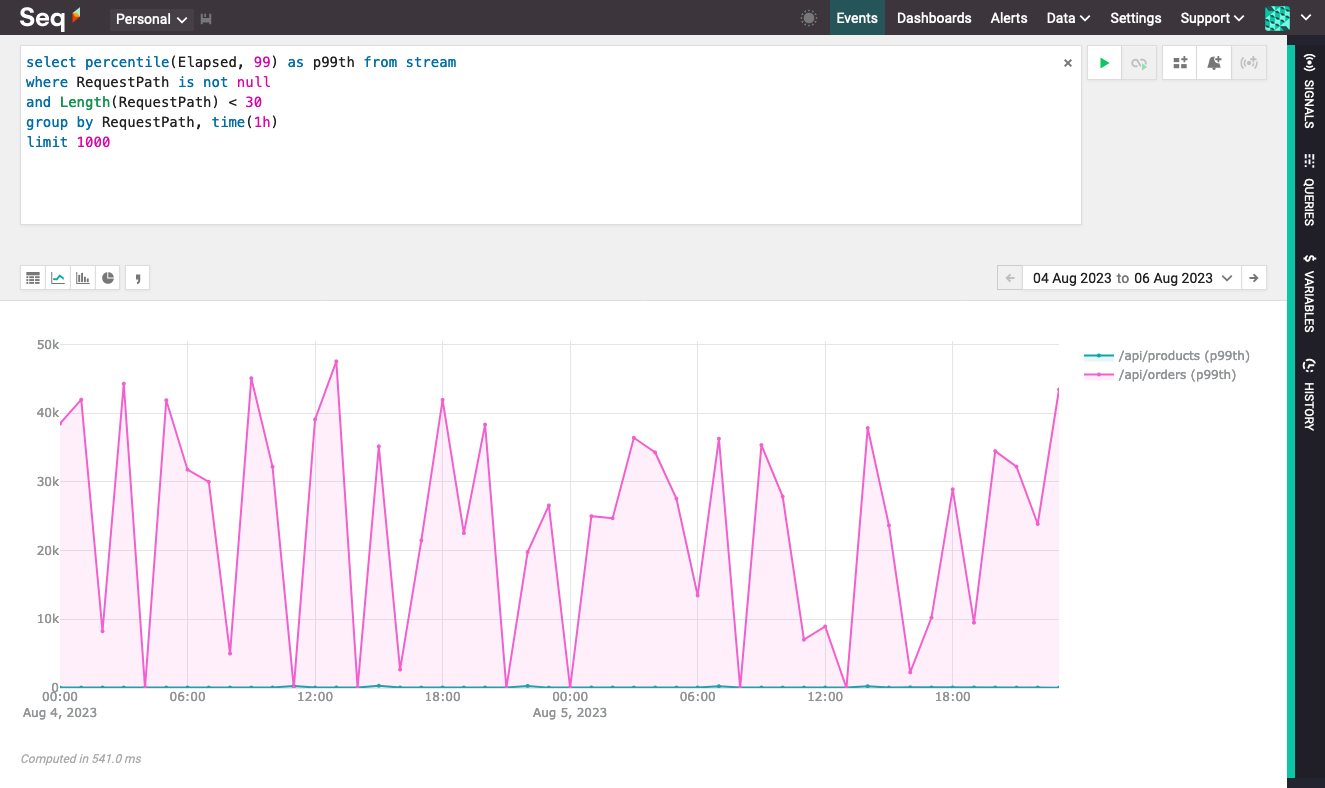
99th percentile response time as a timeseries chart
In queries that group by time(), one further function becomes available:
interval()- this function evaluates to the duration of each time slice; the result is in the same units as duration expressions (like1d), and can be manipulated using functions likeTotalMilliseconds(interval())
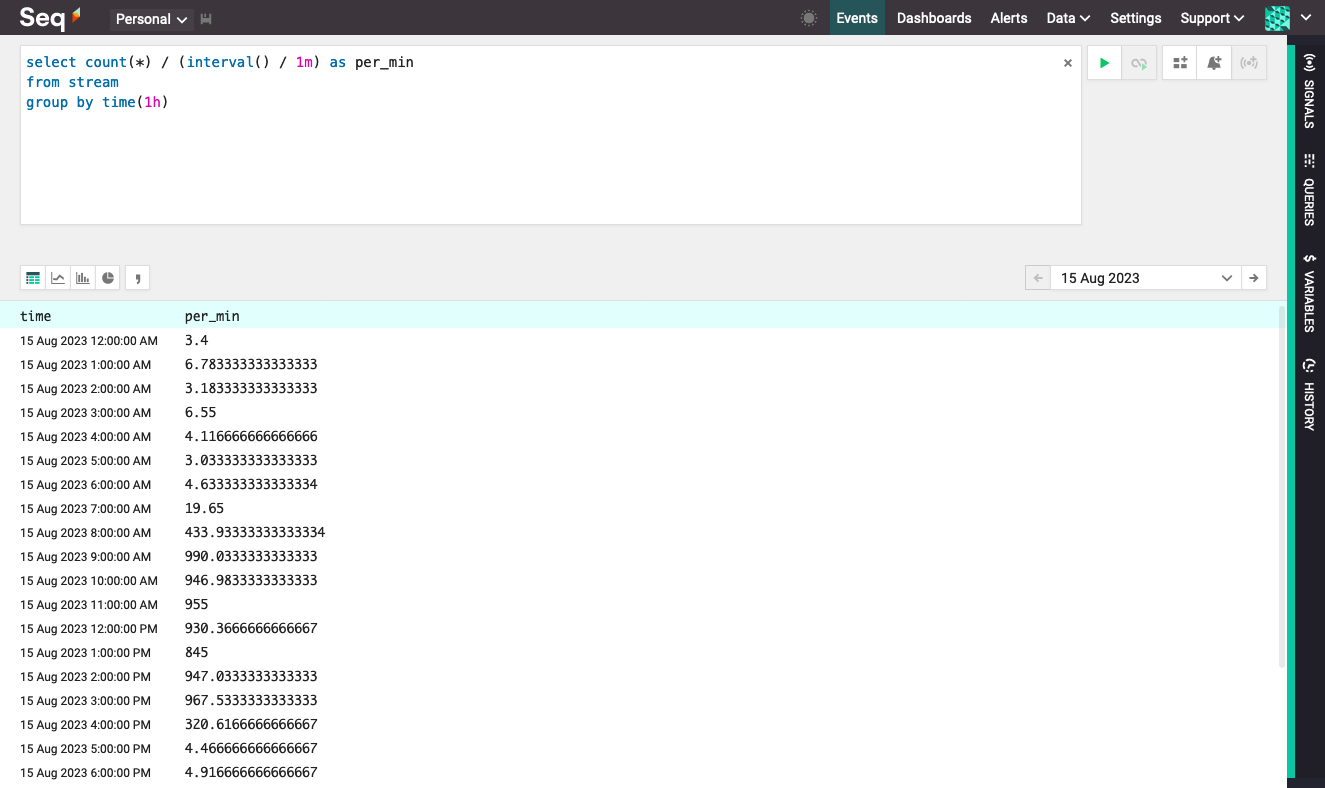
Using the interval() function in a query
Lateral cross joins
Seq supports lateral cross joins and the unnest() set function, which allow an array in the source data to be expanded into one row per element.
The query below expands a Title property and Tags array on the source log event into one row per (Title, Tag) pair in the result set:
select Title, Tag
from stream
lateral unnest(Tags) as TagThe alias introduced in the lateral clause can appear anywhere that properties on the source log event are visible.
Learning more
The documentation in What's Next below has more detail on many of the topics here. If you have questions or need help writing a specific query, please get in touch with the Seq team at Datalust - our support channels are linked from the Support menu in the Seq navigation bar.
Updated 2 months ago