Managing Storage
Making sense of how Seq stores event data on disk
Data > Storage gives you an idea of how effectively retention policies are reclaiming disk space. It includes a chart that shows how much space is being used now by events ingested in the past. It doesn’t track disk usage over time, which should remain fairly constant on a healthy server.
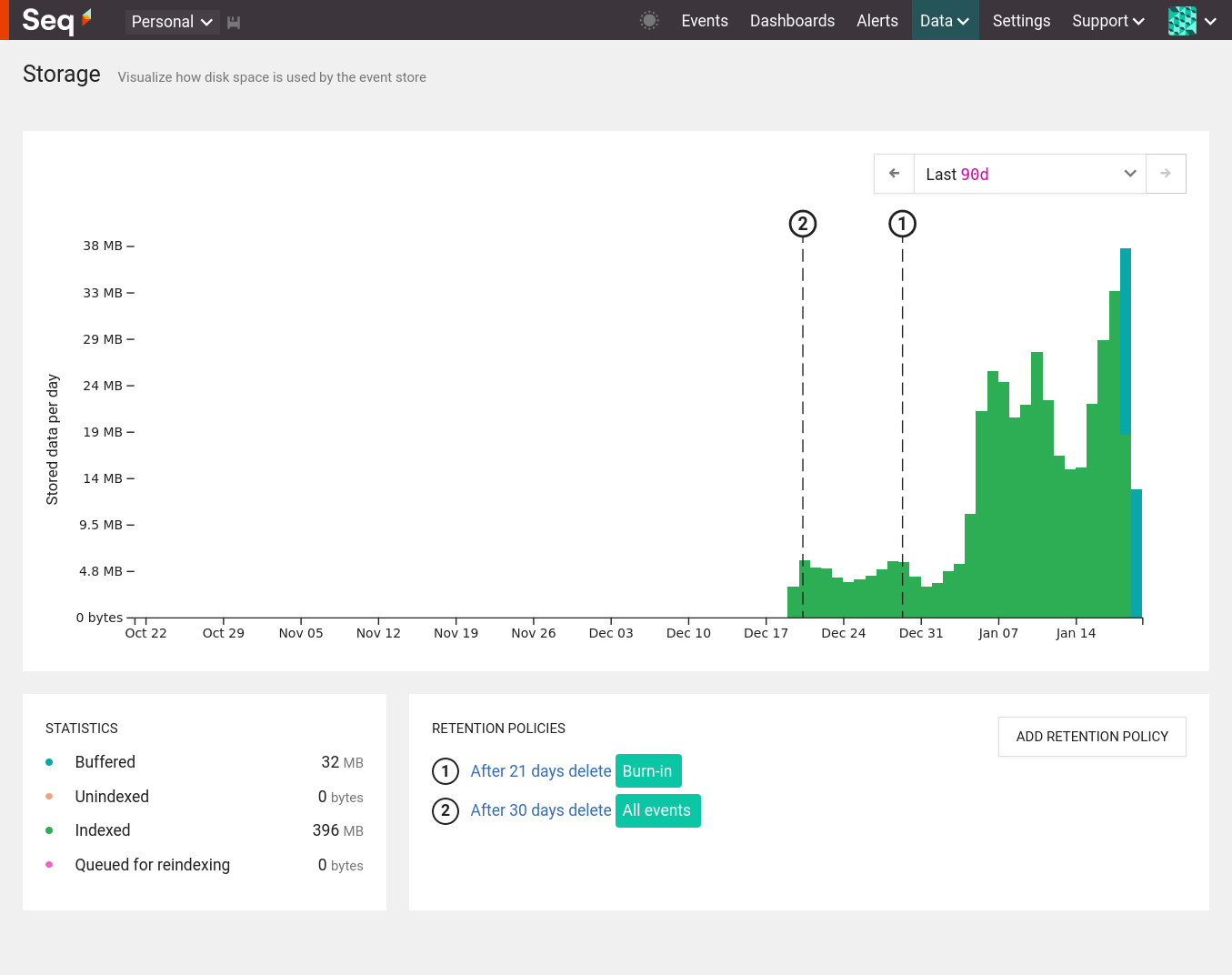
The Seq storage view showing indexed data for the last 90 days
Interacting with the chart
The storage chart defaults to showing all data by day. You can change the time range to view more recent data in greater detail.
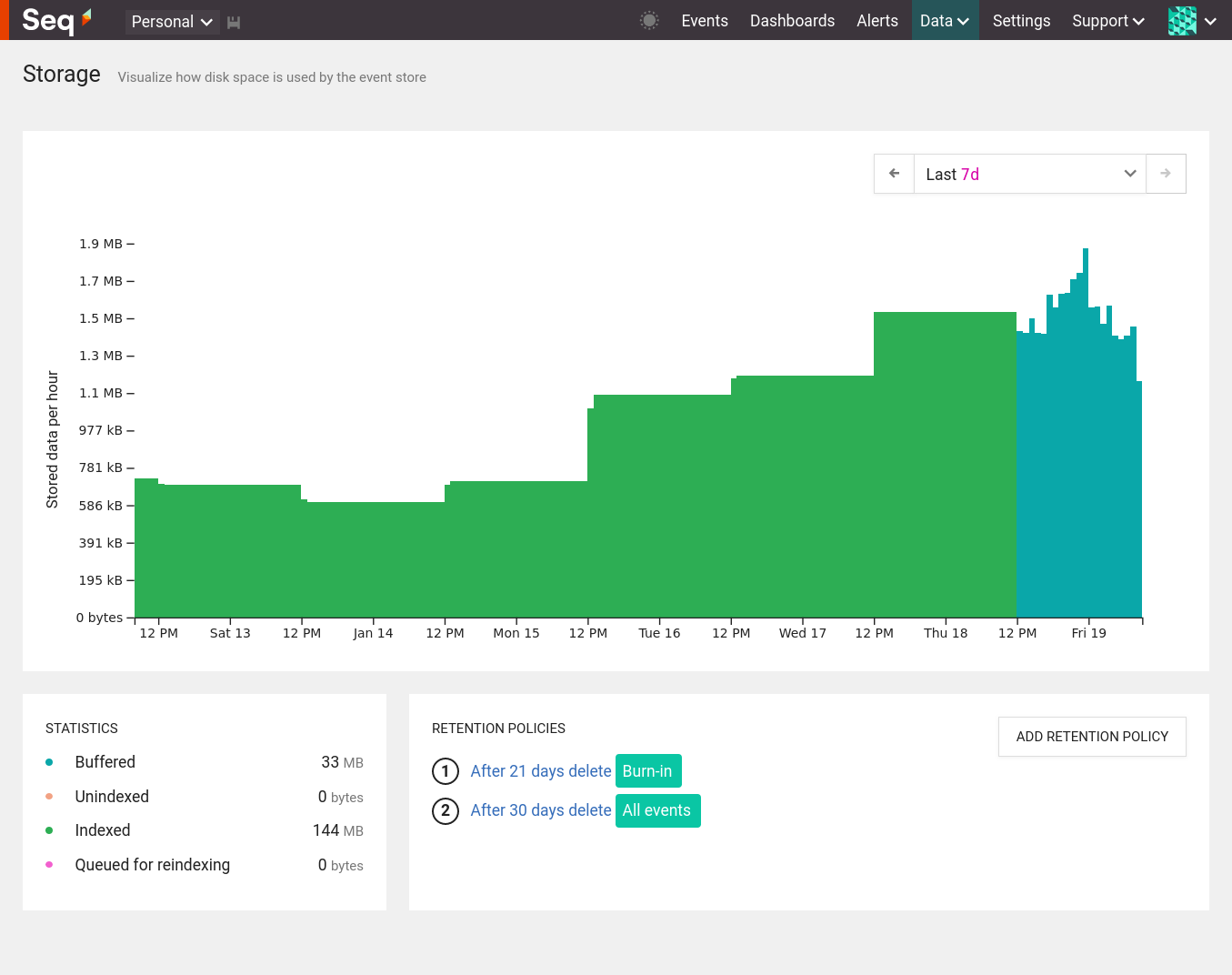
The storage view chart showing indexed and buffered data for the last 7 days.
Interpreting the chart
Statistics
The Storage View visualizes event data that may be stored on disk in one of a number of states.

Storage view statistics indicating 1.4 MB of buffered data, 50 MB of indexed data, and 1MB of indexes
- Buffered: Represented as a blue shaded area on the chart. Just ingested and out of order.
- Indexed: Represented as a green shaded area on the chart. Coalesced and indexed. This is the state most of the stream should be in.
- Unindexed: Represented as a yellow shaded area on the chart. Coalesced but not yet indexed. This happens approximately every 10 minutes.
- Queued for reindexing: Represented as a pink shaded area on the chart. Coalesced but indexes are out of date. These are updated approximately every 10 minutes with unindexed data. This happens to all data when signals/indexes are created or modified.
- Indexes Represented as a purple shaded area on the chart. Storage used for indexes.
Are retention policies reclaiming space?
If retention policies are effective you should notice a drop in the area under the chart at the point where the policy is applied.
If retention policies don’t seem to be effective then you can look at the shape of retained data and see if there’s a different filter that would remove more data as it becomes unnecessary.
Are indexes being churned?
When a signal is created or updated the green indexed portions of the chart will become pink, indicating that there’s reindexing work to do. This is done after retention policies are processed approximately every 10 minutes.
If the chart appears to spend more time pink than green, then I/O bandwidth and core count may need to be increased to improve overall efficiency.
Updated 4 months ago